Topic Contents: Hide
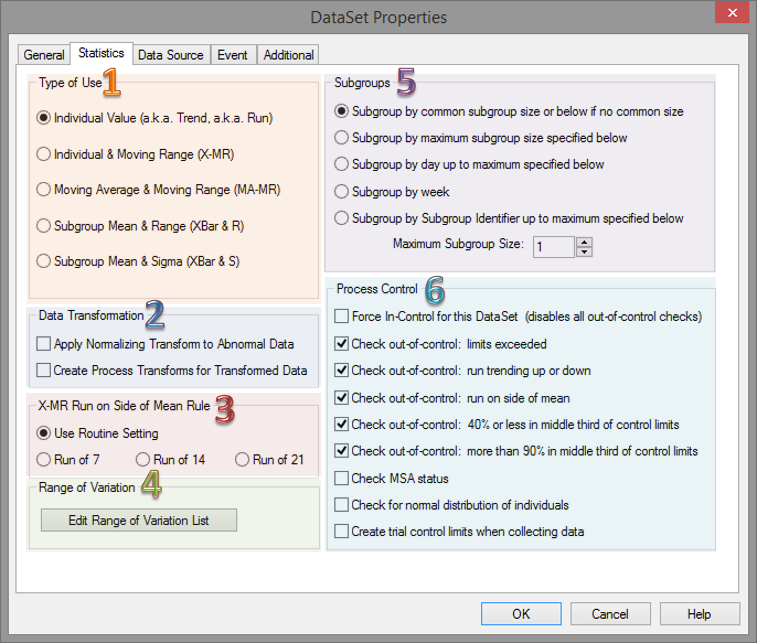
The Statistics tab of the DataSet Properties dialog allows you to select specific statistical controls on the selected DataSet.
A DataSet automatically calculates basic statistical and summary data for each row such as mean, standard deviation, highest value, etc. See the topic DataSet Statistical Values for a complete list.
Click on the image below to learn more about the various sections of this dialog.
Selecting a type of use will determine how your data is calculated in the DataSet and what type of control limit will be created.
· Individual Value (Trend or Run)
· Individual & Moving Range (X-MR)
· Moving Average & Moving Range (MA-MR)
· Subgroup Mean & Range (XBar & R)
· Subgroup Mean & Sigma (XBar & S)
The two Data Transformation options consider all of the values in the current process of a feature characteristic, not just the subset of 30 individuals or 20 subset values as in the Process Control Editor. If either of these options are selected, control limits cannot be calculated for the DataSet.
Transformed data will be re-scaled so that the nominal and one of the spec limits are retained.
This option will determine an appropriate normalizing transform for all of the data in the DataSet. The transform will always be up-to-date, will only apply to the data in the context of the DataSet, and it will not be saved to the database.
"Apply Normalizing Transform to Abnormal Data", is the same as the old "Apply Normalizing Transform".
This option determines an appropriate normalizing transform for all of the data in the DataSet. However, in this case, the transform is recalculated only when the option is selected on the dialog, will be saved with the features, and be applied to the data wherever those features are accessed.
In an X-MR chart, when the number of consecutive points on one side of the mean meet or exceed the rule selected, the markers of the points will use the Side of Mean style in the Series dialog.
When the radio button next to Use Routine Setting is selected, the Run on Side of Mean Rule in the Control tab of the Routine Properties dialog will be used.
When the Use Routine Setting radio button is cleared and Run of 7, Run of 14, or Run of 21 is selected, the selected rule will be applied to the DataSet.
To use the Range of Variation variables the DataSet property for range of variation tolerance percentage needs to be set. This value will default to 50 percent. CM4D will refer to this value as the ROV percent value that can be reported with the CM4D variable ~rovpercent~ and herein after referred to as ROV%. The ROV Percentage defines the size of the acceptable range of values. An ROV% value of 50 represents 50 percent of the tolerance which can be expressed in the following equation: tolerance * (50/100).
Refer to the topic DataSet Range of Variation for more information on ROV.
To set the percentage values for the default ROV, or to add additional ROV% values, click Edit in the Range of Variation section on the bottom left corner of the Statistics tab. In the Range of Variation Edit dialog, you can calculate and report multiple ROV's based on different tolerances and/or percentages.
· There is no fixed limit to the number of ROV's which may be entered.
· ROV labels are case sensitive, so any upper case labels are forced to lower case to avoid problems involving case.
~rovcenter~
~dataset,rovcenter,rov60~
~rovcenterrov40~
~rovspread~
~dataset,rovspread,rov60~
~rovspread,rov40~
~rovtarget~
~dataset,rovtarget,rov60~
~rovtarget,rov40~
<default ROV value>
<ROV value> + label “rov60”
<ROV value> + label “rov40”
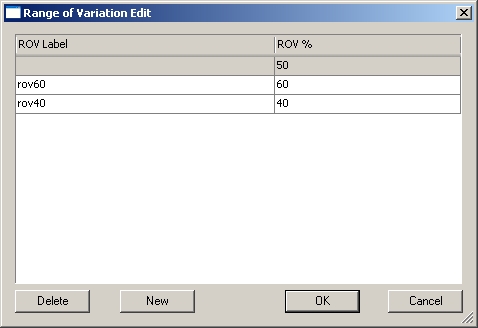
Double click the <new> label and enter your label. Double click the ROV value to enter the ROV%.
· Delete - Select the row of the ROV that you want to remove from your DataSet, and click Delete.
The default (first row) ROV cannot be deleted.
· New - Creates a new ROV.
When CM4D needs the subgroup size to use for the data, and the DataSource is a DataSet, CM4D will look at the Default Subgroup Size on all of the routines and subroutines of the query that is referenced by the DataSet.
Subgroup selection in the DataSet will override the Routine Default Subgroup settings.
For more information about subgroups, see the topic Subgroups.
· Subgroup by common subgroup size or below if no common size - When this radio button is selected, CM4D will determine if the routines and subroutines in a query have common subgroup sizes. If the Default Subgroup Sizes for all of the routines and subroutines have a common value (i.e. they have the same value), then the common value will be used for the subgroup size. However, if the Default Subgroup Sizes of the routines and subroutines are not all the same value, then the subgroup size will be set to the Maximum Subgroup Size.
· Subgroup by maximum subgroup size specified below -
· Subgroup by day up to maximum specified below -
· Subgroup by week -
· Subgroup by Subgroup Identifier up to maximum specified below -
· Maximum Subgroup Size - Enter a maximum subgroup size to be used if one of the subgroup options indicating "specified below" is selected and the conditions requirements are met.
The minimum number of subgroups for calculating Cpk is three, and the minimum number of values needed to calculate Cpk is ten.
Selecting a Process Control method in the settings of the DataSet overrides the routine settings.
· Force In-Control for this DataSet (disables all out-of-control checks) - disables all the Check out-of-control options.
· Check out-of-control: limits exceeded -
· Check out-of-control: run trending up or down -
· Check out-of-control: run on side of mean -
· Check out-of-control: 40% or less in middle third of control limits -
· Check out-of-control: more than 90% in middle third of control limits -
· Check MSA status -
· Check for normal distribution of individuals - checks to make sure that the data is normal. If the data is abnormal, neither process Cp values or run Cp values will be available.
· Create trial control limits when collecting data -
Check MSA status, Check for normal distribution of individuals, and Create trial control limits when collecting data are independent from the Check out-of-control options, so they are always enabled.