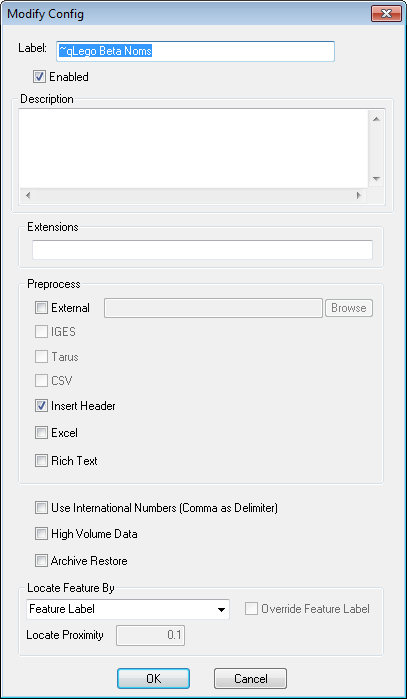
The Modify Config dialog contains the properties available for the Config.
Enter a new label for the Config.
Each time data is processed by a translator, all enabled Configs are checked to see if the data fits the set requirements. If a Config is disabled, it will remain in the tree, but will not be checked when data is processed. Disabled Configs appear as highlighted red with white text.
An optional description of the Config may be entered in the Description field.
The Extensions field may be used to exclude any unwanted file types automatically when loading data files into a Config. To indicate specific file extensions you want to allow, enter just the extension into the field (no periods), separated by a comma or semicolon. The file extensions 4datasmith, 4jr, 4jx, and [~4j_tmp~]_ are always ignored when adding files to a Config.
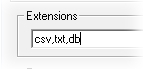
For the settings shown in the image above, the file types that would be included would be *.csv, *.txt, and *.db files.
Preprocessing is any processing DataSmith does on a data file without putting the data in the database. Preprocessing can be done on your data files by selecting options within the Modify Config dialog.
When DataSmith does any type of preprocessing, a temporary file will be created. The string [~4j_tmp~]_ will be added as a prefix of the file name, and the extension will be changed to *.[~4j_tmp~]_(original file type extension).
Original file: q1000 Sample Two.txt  DataSmith Temp file: [~4j_tmp~]_q1000 Sample Two.[~4j_tmp~]_txt
DataSmith Temp file: [~4j_tmp~]_q1000 Sample Two.[~4j_tmp~]_txt
DataSmith usually cleans up the temporary files, but occasionally they may be left. If this happens, and you are sure they are not being used, you can delete them safely as they are no longer needed. If the temporary files are active, you will not be able to delete them.
The External option for Preprocessing allows you to write a user-defined script to pre-process data files that otherwise cannot be read by DataSmith.
An example of such a file would be a script that converts PDF files into a file type that can be read by DataSmith.
The script must be able to accept two command line parameters. The first parameter will be the name of input file (with complete path). The second parameter will be the name of the output file (with complete path). The script will be required to open the input file, read the contents, perform the desired processing, and write to the output file. The script will need to create the output file.
If you do not enter the full path to the external file, but only the file name, DataSmith will look for the file in the same folder that DataSmith was started from.
When IGES is selected, DataSmith will prepare the IGES data file so that it can be processed.
When Tarus is selected, DataSmith will prepare the Tarus data file so that it can be processed.
When CSV is selected, DataSmith will prepare the CSV data file so that it can be processed.
Insert Header is an internal Preprocessing method in which DataSmith will insert information about the file into the beginning of the file. After the Insert Header box is checked, the DataSmith document needs to be saved, then closed and reopened to view the header information. Below is an example of the information that is inserted at the beginning of a data file when the Insert Header check box is selected.
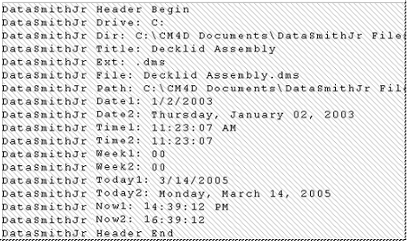
The drive, directory, title, file extension, filename and path are provided. Then, the creation date of the file is provided in abbreviated and complete formats. Two different time stamp formats are provided. The week number labeled Week1 starts on a Sunday, and Week2 starts on a Monday. The current date is provided in abbreviated and complete formats. To remove the header information from the beginning of the data file, clear the check box next to Insert Header, then save, close, and reopen the data file.
Microsoft Excel must be installed on the system that is running DataSmith in order for the Excel preprocessor to work.
Excel is an internal Preprocessing method used by DataSmith to read Microsoft Excel documents (*.xls or .xlsx).
· The Excel preprocessing is upwards compatible from Excel 2000.
· The version of Excel that is installed on the workstation running DataSmith must support .xlsx files in order for DataSmith to read them.
· Make sure that the file is not already open in Excel when DataSmith is trying to read the file.
Excel documents may still be preprocessed using an External Preprocessor, but would require a separate script in order to be able to load .xls or .xlsx data files.
If there is more than one worksheet within an Excel workbook, all of the worksheets will be processed (starting with the first worksheet, not the sheet that is open when saved) as a single file in DataSmith.
Rich Text is an internal Preprocessing method used by DataSmith to read Rich Text Format (*.rtf) files.
When Use International Numbers is selected, commas will be used as delimiters instead of decimals.
High Volume Data Processing can be used to put data in your database quicker. High Volume Data Processing is a considerably faster way to manage data in the database. It is faster because it restricts the way the data goes into the database, making it more compact.
The Archive Restore option is enabled when data that has been archived using Data Archiver is read back into the Database. The Archive Restore option in the Config Properties will stamp all of the data that is being put back into the Database with the "Restore" flag.
If a feature does not have a feature label defined, DataSmith can use the Locate Feature By option to match features by either the XYZ Nominal or Actual values.
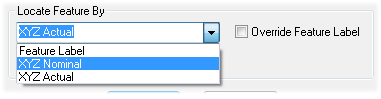
The numerical field used with the Locate Feature option defines how close a value must be to be considered a match. The numeric value is a proximity distance in the units of the data being processed. Locate Feature by XYZ may be used to locate Reference Features.
Zero is a valid entry.
In order for the Locate Feature By options to work, the feature must:
· exist in the database (features cannot be added to a database using this method)
· not have a feature label defined
· have nominal or actual XYZ values assigned to the feature